


The future is now: four insights from CZ Biohub Chicago’s inaugural scientific conference
Researchers gathered to discuss trends and technologies that will enable biological research





Scientists have made great strides in understanding the complexity of the cell in the nearly 360 years since English polymath Robert Hooke discovered this smallest unit of life. The anatomy of the cell and functions of its various internal structures, or organelles, are far less obtuse than they once were—even schoolchildren now confidently proclaim that mitochondria are the “powerhouses” of the cell.
In 2001, extraordinary advances in technology and molecular biology led to the first-draft sequence of the entire human genome, revealing the genetic code for the approximately 20,000 different proteins that allow our cells to function. But we still have much to learn about what the majority of those proteins do and where they are located in the cell.
For the past five years, a team of Biohub scientists, in collaboration with researchers at the Max Planck Institute of Biochemistry in Munich, Germany, have been working to close this massive knowledge gap, one protein at a time, through a project called OpenCell.
“What OpenCell aims to do is create a complete map of how a single human cell is wired,” says Manuel Leonetti, a CZ Biohub group leader and principal investigator on the OpenCell team, which has now published data in Science on the first 1,310 proteins they’ve characterized.
The steps to understanding how a cell works are not unlike those we would take if we knew nothing of how a car works other than a parts list, Leonetti says. Thanks to the foundation laid by the Human Genome Project, scientists know what most of the proteins, or “parts,” of the cell are, but they still don’t know where many of those proteins are or what other proteins they must interact with in order for the cell to work properly. “We have a parts list, but we need a blueprint,” he explains.
Without understanding how all of the proteins work in a healthy cell, it’s very challenging to understand what causes cells to malfunction, or why mutations in specific genes cause disease, he says. “The cell is a very complex set of interconnected molecular machines, and if we don’t really understand all the different connections between them, we can’t really understand what happens when one of these units is broken.”
But it takes a village to map the cell, and along with senior author Leonetti, plus Matthias Mann and members of his Max Planck lab, more than 20 current or former Biohubbers are involved in the new Science paper.

Matthias Mann
Photo: Friedrun Reinhold
Nathan Cho, Keith Cheveralls, Kibeom Kim, and Preethi Raghavan of the Biohub are joined as co-first authors on the paper by Andreas-David Brunner and André Michaelis, who worked on the project in Munich. Other Biohub authors include Hirofumi Kobayashi, Laura Savy, Jason Li, Hera Canaj, James Kim, Edna Stewart, Christian Gnann, Frank McCarthy, Joana Cabrera, Bryant Chhun, Marco Hein, Shalin Mehta, Rafael Gómez-Sjöberg, Daniel Itzhak, and Loïc Royer. CZ Biohub Investigator Bo Huang, of UC San Francisco, also took part in the work, as did the Whitehead Institute’s Jonathan Weissman, former UCSF graduate student Rachel Brunetti, and Greg Dingle, who participated in the project as a software engineer at the Chan Zuckerberg Initiative.
“Every single one of them had a very important contribution, from the people who did the molecular work to the people who wrote the code or built the website,” Leonetti says. “At its core, OpenCell is a perfect example of team science.”
To find a protein’s location in the cell, the OpenCell team used a tool known as split-mNeonGreen2, developed in collaboration with Huang in 2017. This tool allowed the researchers to create a library of CRISPR-edited cells that contain protein tags that make the protein fluoresce under a microscope.
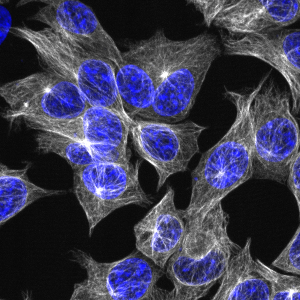
In an image from the OpenCell database, microtubule-associated protein 4 (MAP4) is clearly visible in white and gray in a group of cells. Cell nuclei appear in blue.
The method eliminates the need for cloning DNA using plasmids—a labor-intensive method often used in more traditional genetic sequencing protocols. As part of this protein-identification and localization process, the team developed a software program that allows the user to create a custom CRISPR protocol specific to a targeted protein.
To better visualize the proteins, the researchers developed a machine-learning algorithm that directed a fluorescence microscope to automatically adjust the imaging settings and to move the lens around to capture the best images of live cells as they grow in 96-well plates. This method not only standardizes the process of imaging the cells, but is also far quicker than a scientist doing the same work. In the resulting images, all viewable at opencell.czbiohub.org, cell nuclei appear in blue, and proteins are clearly visible in white.
The second key step to revealing the cellular blueprint is to figure out how each protein interacts with other proteins in the cell. The OpenCell team uses a technique called immunoprecipitation mass spectrometry to pull each protein of interest out of the cell along with any other proteins that are attached to it. That information has allowed the researchers to draw a map of protein–protein interactions, which is crucial to understanding the workings of the cell. For this step, Leonetti partnered with Mann and his team at Max Planck, who are pioneering the development of highly sensitive, high-throughput mass spectrometry technologies.
Using these techniques, Leonetti and his colleagues can now fully map about 100 proteins per week, but they aim to significantly pick up the pace. “We’re building our own automation robots to be able to do this work much faster,” Leonetti says, “but first we needed to do the work ourselves, manually, so we could think very hard about what we could improve and how we could make better choices to increase the throughput. I was lucky to work with a fantastic team of colleagues who were not intimidated by the scale of our experiments.”
So far, the OpenCell team has mapped more than 1,300 different proteins, but Leonetti and his colleagues hope to do even more for the remaining 18,000.
For example, one of the next steps in the project is to take stationary protein blueprints to the next level, with video recordings that will allow scientists to see proteins in action.
“The cell is an extremely dynamic object,” Leonetti says. “I think it’s going to be a lot of fun to not just have all these static images, but movies that show you how different proteins are moving in the cell, such as all the crazy protein reorganization that happens during cell division.”
Another goal of the project is to increase the diversity of the cell types the team is analyzing. At the moment, the researchers are relying on HEK293T, a resilient human kidney-cell line that’s very commonly used in biological research. These cells have been mutated and transformed so they’re easy to manipulate and grow in the lab, but that means they’re not necessarily the best representation of normal human cells, Leonetti says.
The OpenCell team are also now looking to shift their work toward induced pluripotent stem cells, or iPSCs, which can be obtained from adult human skin and reprogrammed to make any cell type in the body. This will allow the researchers to make cell type–specific maps of the proteome that will be useful for disease research. “Mapping how cells are built is a very complex problem that will keep us busy for some time and will require a diversity of approaches being applied in parallel,” says Leonetti. “What is exciting is that multiple large-scale efforts, OpenCell being one of them, are being launched to tackle this complex question. We are lined up to make rapid progress.”
At its core, OpenCell is a data-science project, Leonetti says, at a scale that’s not often pursued in most traditional academic settings because it can be hard to get funding for such an endeavor. However, CZ Biohub is built upon the goal of supporting fundamental scientific research and new technology development, making it the perfect place for such a project.
It’s because of this diverse set of skills and expertise from both the Biohub and Max Planck—spanning cell biology, microscopy, mass spectrometry, robotics, data science, and more—that OpenCell is even possible, he says. “It would have been very hard for me to find the same level of multidisciplinary expertise at other places.”
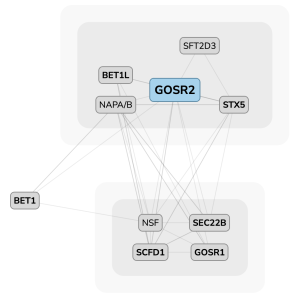
A protein–protein interaction map for GOSR2 (Golgi SNAP receptor complex member 2) from OpenCell data. Mutations in GOSR2 are implicated in a rare form of epilepsy.
As with all CZ Biohub projects, a central goal of OpenCell is to make the data freely available, which Leonetti and his team are doing through the user-friendly OpenCell website, which includes all the proteome mapping data they have amassed thus far. Users can search for a specific protein or groups of proteins, and can view microscopy images showing where the protein is located in the cell, accompanied by a diagram that depicts protein–protein interactions. Users can also access and download any and all of the images, coding tools, and specific protocols used by the OpenCell team.
“If anybody wants to recreate our analysis, everything they need is there,” Leonetti says.
Leonetti and his team hope other scientists will find the data useful for answering their own scientific queries, or perhaps to discover something new.
“Our hope is that people are going to go on our website, carefully look at our images or our interaction data and find some surprising results. And maybe pursue a research project on the basis of something that they uncovered by looking at our data,” Leonetti says, adding that some colleagues have told him that OpenCell data has already validated hypotheses they had about particular proteins. “This is our dream—that we inspire other people for their own science.”
Researchers gathered to discuss trends and technologies that will enable biological research
Learn More
In the last couple decades, Malaysia has emerged as a global hotspot for neuroinfections such as encephalitis. Now a team from Universiti Malaya is...
Learn More
Yasin Şenbabaoğlu, CZ Biohub SF’s new Director of Computational Biology, is working to reveal hidden patterns in health and disease
Learn More
Stay up-to-date on the latest news, publications, competitions, and stories from CZ Biohub.
Marketing cookies are required to access this form.

